[REV][Rainbom Bash Adventure]
We are given a game called Rainbombashadventure, made with a game engine called Ren’Py

After escaping a long conversation between characters, I had to choose paths to clouds, given the distances, the win/lose condition is determined based on my choices
I will explore the game folder

the script.rpy file contains the whole game logic including win or lose conditions
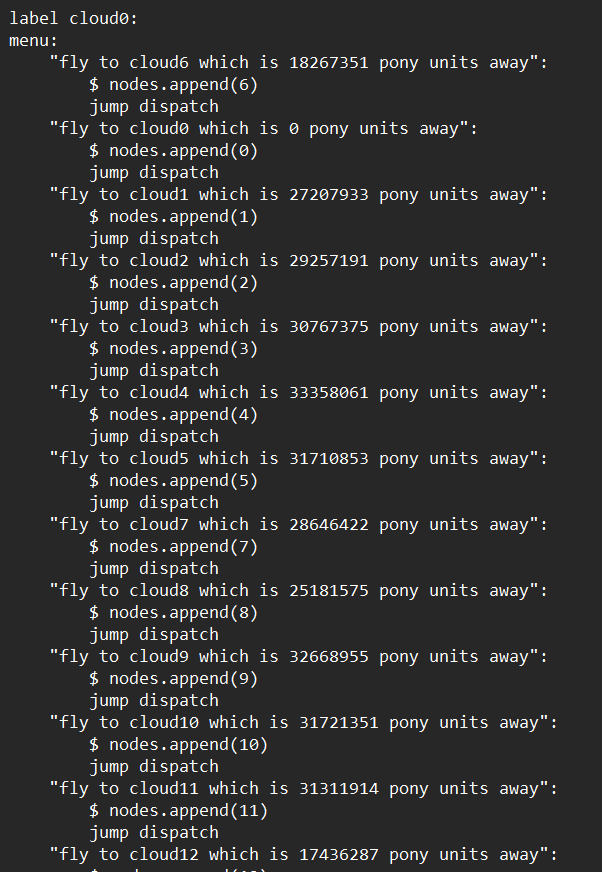
This is cloud0 menu, which displays the distances between it and the others, same for the rest of the clouds
It is a Travelling Salesman Problem
And here is the important part that determines our win condition->
label ending:
python:
import hashlib
flag = b""
def xor(target, key):
out = [c ^ key[i % len(key)] for i, c in enumerate(target)]
return bytearray(out)
def key_from_path(path):
return hashlib.sha256(str(path).encode()).digest()
def check_path(path, enc_flag):
global flag
flag1 = xor(enc_flag, key_from_path(path))
flag2 = xor(enc_flag, key_from_path(list(reversed(path))))
if flag1.startswith(b"BtSCTF"):
flag = flag1
print(flag)
flag = bytes(flag).replace(b"{", b"{{").decode('ascii')
return True
if flag2.startswith(b"BtSCTF"):
flag = flag2
print(flag)
flag = bytes(flag).replace(b"{", b"{{").decode('ascii')
return True
return False
is_correct = check_path(nodes, bytearray(b'\xc2\x92\xf9\xf66\xe8\xa5\xa6\x17\xb6mGE\xcfQ\x90Mk:\x9a\xbb\x905&\x19\x8e\xc4\x9a\x0b\x1f\xf8C\xf4\xb9\xc9\x85R\xc2\xbb\x8d\x07\x94[R_\xf5z\x9fAl\x11\x9c\xbb\x9255\x08\x8e\xf6\xd6\x04'))
if is_correct:
rb "all cloudz smashed im the queen"
rb "i got 100% swag"
"[flag]"
else:
"Sadly, Rainbom Bash was too slow and wasn't able to smash all clouds."
return
The program decrypts the flag with the path (nodes) chosen, so the right path will successfully decrypt the flag!
btw, Travelling salesman problem is an np hard problem, which means it can not be solved in polynomial time, but for a small number of nodes, it can be solved (not guaranteed) using a greedy algorithm
solver like this may work -> https://github.com/dmishin/tsp-solver
But first, we need to extract the matrix of distances between clouds. I wrote a simple regex to grab and add it to the matrix
import re
import numpy as np
def get_the_distance_of_nodes(code):
debu=[]
distance=np.zeros((20,20))
for clound_num in range(20):
regex_for_spilt = f"label cloud{clound_num}"
splitawy_first_position=re.search(regex_for_spilt, code)
if splitawy_first_position:
start_pos=splitawy_first_position.start()
if clound_num < 19:
end_pattern = f"label cloud{clound_num + 1}:"
end_match = re.search(end_pattern, code)
if end_match:
end_pos = end_match.start()
else:
end_pos = len(code)
else:
end_pattern = "label ending:"
end_match = re.search(end_pattern, code)
if end_match:
end_pos = end_match.start()
else:
end_pos = len(code)
section_text = code[start_pos:end_pos]
regex_for_label=re.compile(r'label cloud (\d)')
#regex_for_distance=re.compile(r'(\d)\spony')
regex_for_cloudy=re.compile(r'cloud(\d*) which is (\d*) pony units')
c_d=regex_for_cloudy.findall(section_text)
n_c=regex_for_label.findall(section_text)
#print(c_d)
for c in c_d:
#this is only for debugging
debu.append(clound_num)
distance[clound_num,int(c[0])]=int(c[1])
if(int(c[1]))==0:
#debugging
print(f"cloud_num={clound_num},to which cloud = {int(c[0])},distance = {int(c[1])}")
return distance,debu
now using the mentioned library to solve it ->
from tsp_solver.greedy import solve_tsp
print("the path is - > ")
path=solve_tsp(r,endpoints=(0,0))
print(path)
path is : [0, 12, 15, 2, 1, 5, 11, 14, 17, 7, 19, 13, 9, 10, 3, 8, 16, 18, 4, 6, 0]
Now, replicate the code in the game file to decrypt the flag
def xor(target, key):
out = [c ^ key[i % len(key)] for i, c in enumerate(target)]
return bytearray(out)
def key_from_path(path):
return hashlib.sha256(str(path).encode()).digest()
enc_flag = bytearray(
b'\xc2\x92\xf9\xf66\xe8\xa5\xa6\x17\xb6mGE\xcfQ\x90Mk:\x9a\xbb\x905&\x19\x8e\xc4\x9a\x0b\x1f\xf8C\xf4\xb9\xc9\x85R\xc2\xbb\x8d\x07\x94[R_\xf5z\x9fAl\x11\x9c\xbb\x9255\x08\x8e\xf6\xd6\x04')
path = [0, 12, 15, 2, 1, 5, 11, 14, 17, 7, 19, 13, 9, 10, 3, 8, 16, 18, 4, 6, 0]
path_rev=path[::-1]
flag1 = xor(enc_flag, key_from_path(path))
flag2 = xor(enc_flag, key_from_path(path_rev))
if flag1.startswith(b"BtSCTF"):
print(flag1.decode('ascii'))
elif flag2.startswith(b"BtSCTF"):
print(flag2.decode('ascii'))
BtSCTF{YOU_are_getting_20_percent_c00ler_with_this_one_!!_B)}
[REV][TRANSLATOR]
We are given an ELF file and an encrypted flag: 幾湂潌蕔䩘桢豝詧䭡䝵敯䡨剱挧䍩硷穏罣㈡䨥贇
The program encrypts our input, and after some interaction with it, I found that,
1-every two characters produce one encrypted character, and if u input one character only, it will also produce one encrypted character
2-it is position dependent

It seems that the last input characters are encrypted without getting affected by position, before that, it is affected
Let’s examine the program in depth using IDA

The program takes the input as the second argument, pointed to by the v3 pointer. The program loads 2 bytes each time, then calls the main function, which holds the encryption algorithm
It seems like function sub_1270 does something to (v3 + 1, which holds the second char of the input parameter to the main function, then the return will be used in encryption.
I examined the sub_1270 function, and it works as follows:
so if the first byte is found , it does return first byte>>4 if second byte is found , return second byte >>4 + first byte >>4 if third byte is found , return third byte >> 4 + second byte >>4 + first byte >>4 if fourth byte is found , return fourth byte >> 4 + the rest if more than that , it will recursively return the summation of following bytes shifted right by 4
the enryption algorithm - >
the main shifting algorithm v6 is first char v4 is output of function sub_1270 v5 +1 is my second char the encryption is -> high_byte = (first_byte & 0xF0) | ((first_byte + ((function_output + (first_byte >> 4)) >> 4)) & 0x0F) low_byte = (second_byte & 0xF0) | ((second_byte + function_output + (first_byte >> 4)) & 0x0F) unicode = (high_byte << 8) + low_byte + 4096
So from here, we understand that the first bytes of input will be affected, cause of the function sub_1270
We know the last char is ‘}’
that encrypted char is the last one in the given encrypted text
So we can brute force the program using this knowledge as a starting point
Beginning from the reverse order, we’ll incrementally reconstruct the flag, testing two characters every time
import time
from pwn import *
def solvey(right_data):
flag_till_now = "}"
start_index=len(right_data)-2
for i in range(20):
match=False
for first_byte in range(33, 126):
if match ==True:
break
for second_byte in range(33, 126):
try_that=chr(first_byte) + chr(second_byte)+flag_till_now
p = process(['./translator', try_that])
output = p.recvall().decode().strip()
print ("output - > ",output,"length of output- > ",len(output))
print("right_data = ",right_data[start_index:],"length of right data - > ",len(right_data[start_index:]))
if output == right_data[start_index:]:
print("hi , we found it")
print(chr(first_byte) + chr(second_byte) + flag_till_now)
flag_till_now = chr(first_byte) + chr(second_byte) + flag_till_now
start_index=start_index-1
match=True
break
else:
match=False
continue
if not match:
#debug
print("No match")
time.sleep(100)
return flag_till_now
true_data="幾湂潌蕔䩘桢豝詧䭡䝵敯䡨剱挧䍩硷穏罣㈡䨥贇"
flag=solvey(true_data)
print(flag)
This method will take about an hour or something. Another fast approach is to use a hybrid approach between brute-forcing and implementing the same encryption algorithm :
def decodeer(unicode_chars):
ascii_chars = ["}"]
following_high_nibbles = ["}"]
for i in range(len(unicode_chars) - 1, -1, -1):
unicode_val = unicode_chars[i]
result = brute_force_decode(unicode_val, following_high_nibbles)
if result:
first_byte, second_byte = result
following_high_nibbles.insert(0, chr(second_byte))
following_high_nibbles.insert(0, chr(first_byte))
ascii_chars.insert(0, chr(second_byte))
ascii_chars.insert(0, chr(first_byte))
return ''.join((b) for b in ascii_chars)
def brute_force_decode(unicode_val, following_high_nibbles):
val = unicode_val - 4096
valinbinary = format(val, '016b')
print("val in binary", valinbinary, "len(valinbinary)=", len(valinbinary))
high_byte = (val >> 8) & 0xFF
print("high_byte in binary=",format(high_byte, '08b'))
low_byte = val & 0xFF
print("low byte in binary=",format(low_byte, '08b'))
for first_byte in range(32,128):
for second_byte in range(32,128):
tmp=[chr(second_byte)]+following_high_nibbles
function_output = calculate_function_output(tmp)
if check_encoding(first_byte, second_byte, function_output, high_byte, low_byte):
#print(f"we found the first-> {chr(first_byte)} and the second byte -> {chr(second_byte)}")
print("second byte", chr(second_byte), end='')
print(" , first byte",chr(first_byte),"\n")
return first_byte, second_byte
return None
def check_encoding(first_byte, second_byte, function_output, target_high, target_low):
calc_high = (first_byte & 0xF0) | ((first_byte + ((function_output + (first_byte >> 4)) >> 4)) & 0x0F)
calc_low = (second_byte & 0xF0) | ((second_byte + function_output + (first_byte >> 4)) & 0x0F)
return calc_high == target_high and calc_low == target_low
def calculate_function_output(second_char_till_end):
if not second_char_till_end:
return 0
high_nibbles = [ord(b) >> 4 for b in second_char_till_end]
return sum(high_nibbles)
def decode():
message = "幾湂潌蕔䩘桢豝詧䭡䝵敯䡨剱挧䍩硷穏罣㈡䨥"
#print(len(message))
unicode_values = [ord(c) for c in message]
#print(len(unicode_values))
ascii_message = decodeer(unicode_values)
print(f"Decoded flag: {ascii_message}")
decode()
BtSCTF{W0W_it_re4l1ym3aNs$0methIng!!:)}